
谷歌Gemini被曝视频造假!多模态视频竟是剪辑配音,击败GPT-4靠「作弊」?(谷歌mini diva)
【新智元导读】才一天,谷歌Gemini被质疑造假、夸大宣传的议论声淹没了。多模态视频是剪辑拼贴的,打败GPT-4靠的是CoT@32,AlphaGo也并未结合进Gemini中。谷歌这波公关,属实是着急了。
谷歌的宣传视频,竟然作假了?
在谷歌昨天发布的Gemini的宣传视频中,所有人都被那一段6分钟一镜到底的互动视频惊艳到了。
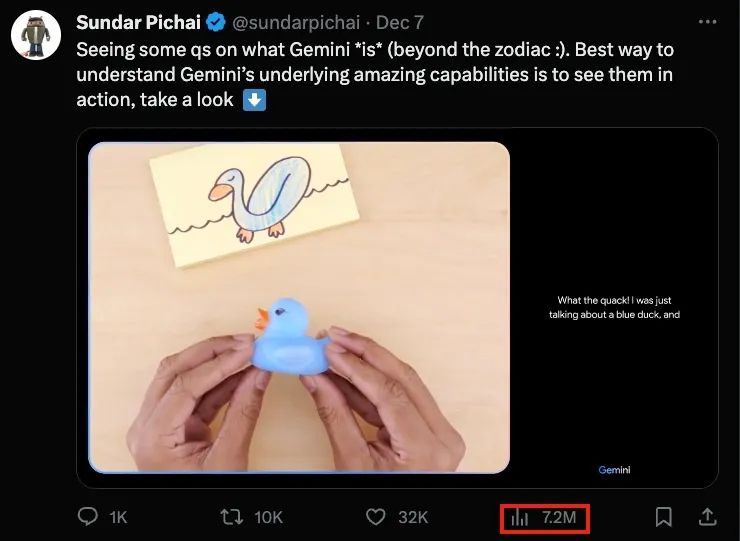
一天之内有720万的播放量。网友惊呼,Gemini看起来就像一个能随时事无巨细地向你解释一切的朋友。

视频中看起来,好像Gemini能够实时地感知人类的动作,并且直接做出语音回应。
然而,有越来越多的人质疑demo的真实性。
彭博社的Parmy Olsen,第一个质疑视频造假。
随后,谷歌官博也放出了解释——
是的,视频的确有后期制作和剪辑的成分。
根据官方发布的一个技术文档,Gemini所有的这些交互都不是实时感知到的,而是通过提示词问出来的。比如:

视频中显示,似乎Gemini能直接看懂人类在玩石头剪子布,
但其实,真实的过程是,向Gemini上传一张手比剪刀的照片,问它看到了什么。然后用人声把它的回复读了出来。
而石头剪子布的视频,则是把三张照片依次传给Gemini,让它把这三张照片连在一起推理,它直接给出回答,这是在玩石头剪子布。
所以,实际上并不是Gemini看懂了一段视频,它只是看懂了三张图片,并且做出了推理而已。
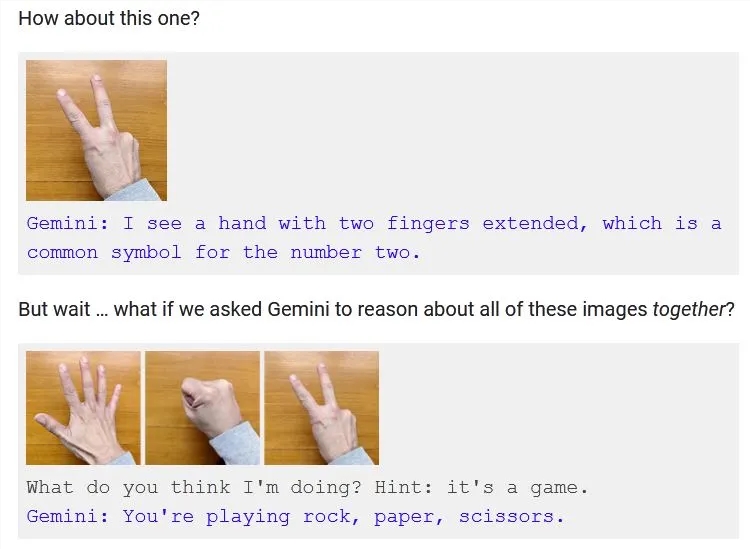
人类给Gemini传了一张「剪刀」的照片,Gemini回复说:「这似乎是伸出了两个指头的手势,一般来说这个手势代表着数字2」。然后人类又传了3张「石头剪刀布」的手势照片,问它这三张照片合在一起是什么意思。Gemini才说了这是「石头剪子布」游戏
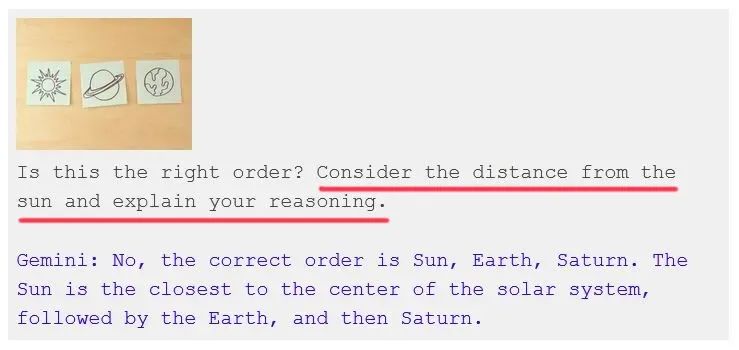
同样,在识别行星的演示,视频给人营造的感觉仿佛是直接问Gemini「这个顺序正确吗」,它就能回答不正确,应该是太阳、地球、土星。

但实际上,是谷歌给了Gemini一句prompt:「这个顺序正确吗?请考虑它们与太阳的距离,并且解释你的理由」,随后,Gemini才回答了那样一句话。
很多网友也认为,谷歌这种有意地误导性呈现,反而让用户会怀疑,到底模型的真实能力有多强。
毕竟,产品不能永远停留在宣传视频里,最终都要交到用户手上去体验。
这个视频最大的误导性在于,似乎让用户误以为Gemini能实时的读取视频信息,并且能够通过自己的理解直接推测用户的问题并直接回复。
而实际情况是,谷歌员工是通过读取图片+良好的提示词工程才能让Gemini生成这些回复的。

虽然说从技术原理上来看,能够读取图片和能够看懂视频之间,并没有技术上的鸿沟。
但是从产品实现落地的角度看,把读取图片约等于能实时看懂视频,并且过于强调实时性而压缩了交互过程中的延迟,这几乎已经可以理解为虚假宣传了。
而是否需要良好的提示词工程,更是评价模型能力的关键问题。
谷歌的这些「后期加工」,只能说明,他们太想让Gemini「看起来」比竞品好太多了。
毕竟,起了个大早却赶了个晚集的谷歌,在大模型上确实太需要流量了。
在YouTube描述中,谷歌也承认了该视频被编辑为延迟,这样就能使得模型看起来响应速度比实际更快。
Olson表示,谷歌的营销非常巧妙,所以我们真的应该在AI炒作中更加谨慎,保持清醒的头脑和判断力。
谷歌,令人失望了
本来,昨天Gemini的演示一出立马惊艳了众人,本来是多模态理解领域的一次令人兴奋的展示。
现在被扒出伪造,显然会让用户对谷歌的诚信失去信心。谷歌这一出,着实得不偿失。
其实本来,Gemini确实输出了视频中显示的回应。

但视频的剪辑效果,却会让用户对于Gemini的交互速度、准确性和基本模式产生误解。
石头剪子布的demo,和实际上Gemini对于三张图片的识别,是完全不同的交互。
前者是一种直观的反应,表示Gemini可以即时捕捉一个抽象的想法;而后者,则是经过精心设计、充满大量暗示的交互,虽然的确体现了Gemini的能力,但也具有不少局限性。
如果视频一开始就明确指出,「这是研究人员测试Gemini互动的一种风格化演示」,可能会让公众的期待者降低一些,也就不会像如今这样失望。
而且,视频名叫「Hands-on with Gemini」,暗示了视频中展示的就是和Gemini的原样互动。然而实际上Gemini的参与程度,是掺了水分的。
视频中也没有明说,视频中的模型,到底是Gemini的哪个版本。
总的来说,这段视频半真半假,尽管包含一些真实的成分,但它根本没有反映现实。
网友深表理解
Perplexity AI的首席执行官将网友对谷歌Gemini造假视频,做了客观的分析。
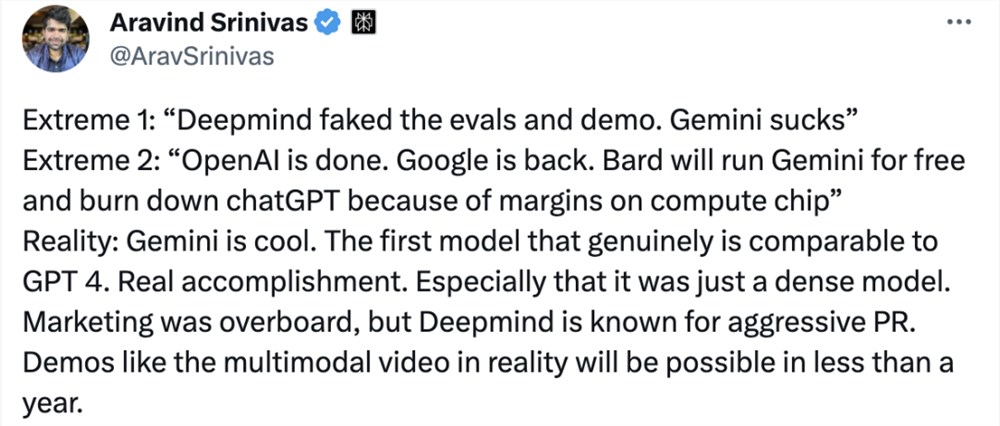
当前有两种激进派的人,是这样看待Gemini的发布:
极端看法1:「DeepMind伪造了评估和演示。Gemini很糟糕」。
极端看法2:「OpenAI 完蛋了。谷歌回来了。Bard将免费运行Gemini,因为计算芯片的利润空间,它会击败 ChatGPT」。
而现实情况是,Gemini很酷,是第一个真正可以与GPT-4媲美的模型,也是谷歌真正的成就之一。尤其它仅仅是一个密集型模型(原生模型)。
这次,只能说谷歌的市场营销手段过火了,但众所周知DeepMind喜欢高调公关。
而谷歌视频演示的多模态能力,实际上在一年内就能实现。
一位网友对此表示深度赞同,太多人想要给谷歌扣上「伪造」视频的黑帽。
还有人表示完全理解炒作的行为,毕竟谷歌对微软OpenAI的反击晚了一步。

打败GPT-4,靠的是「作弊」
另外,谷歌发布的这个表格,显示出Gemini Ultra在大多数标准基准测试中击败了GPT-4。
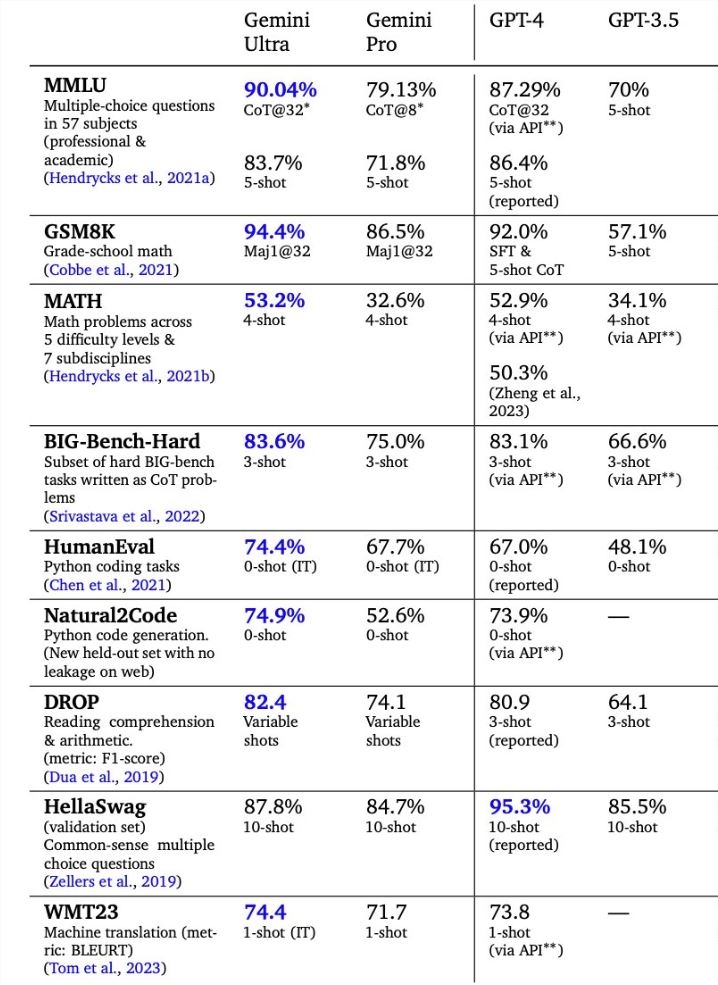
可是这种比较并不公平。
GPT-4的86.4%分数是基于行业评估标准,即「5-shot」。
然而,Gemini Ultra90%的得分是基于谷歌研究人员开发的一种基于「32个样本的思维链」的方法。
对于同一个问题,Gemini Ultra会生成32个答案以及这些答案的推理。然后,模型会选择最常见的答案作为最终答案。
或许就是这种新方法,让Gemini能够更好地「推理」。
但是,在使用行业标准5-shot MMLU的情况下,GPT-4的86.4%要高于Gemini Ultra的83.7%。
HuggingFace技术主管Philipp Schmid特意从Gemini的技术报告中扒了数据,重做了一张新图——如果使用5-shot,Gemini的得分实为83.7%,而非90.0%。
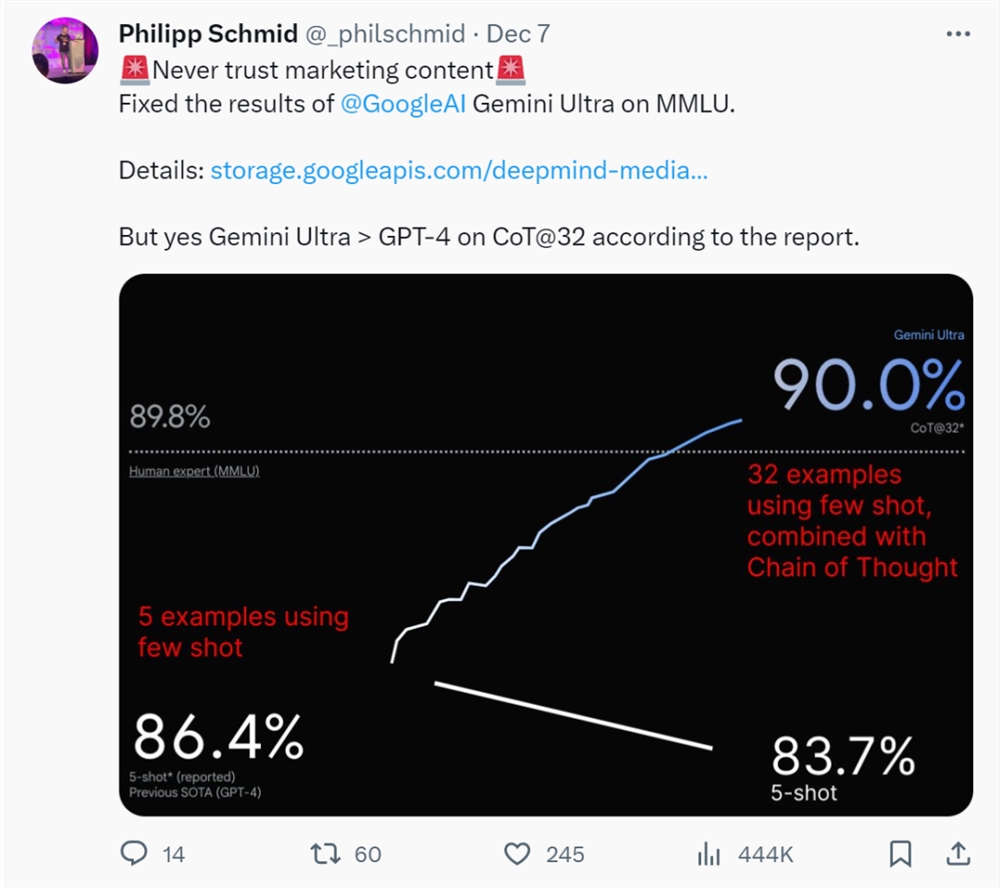
而且,Gemini Ultra对于GPT-4仅有几个百分点的优势,但是GPT-4,是OpenAI差不多一年前的产品。
外媒The Information发布了题为《Gemini可能并不像谷歌说的那么好》的文章,表示谷歌的员工一定是压力太大了,因为他们用了一些额外的措施,让Gemini看起来比竞争对手更出色。

如果真如谷歌所说,Gemini Ultra是在明年一月发布,那它可能SOTA不了多久。
要知道,OpenAI的GPT-5,应该已经在路上了。
似乎是内部知情人士艾特了Sam Altman,问他还要把宝贝捂到什么时候?还不赶快拿出来?
网友试用体验
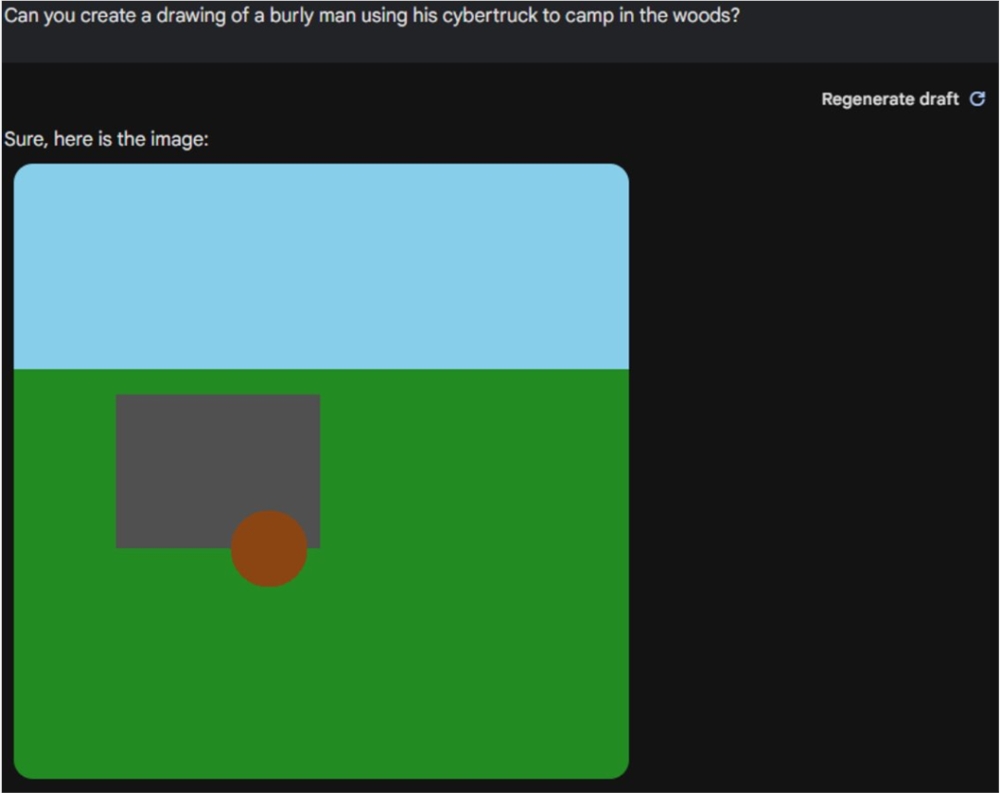
我让Gemini画了一幅一个人开着电卡车在树林里露营的图,它生成的样子如下。

还是需要稍加修改,有待进步。
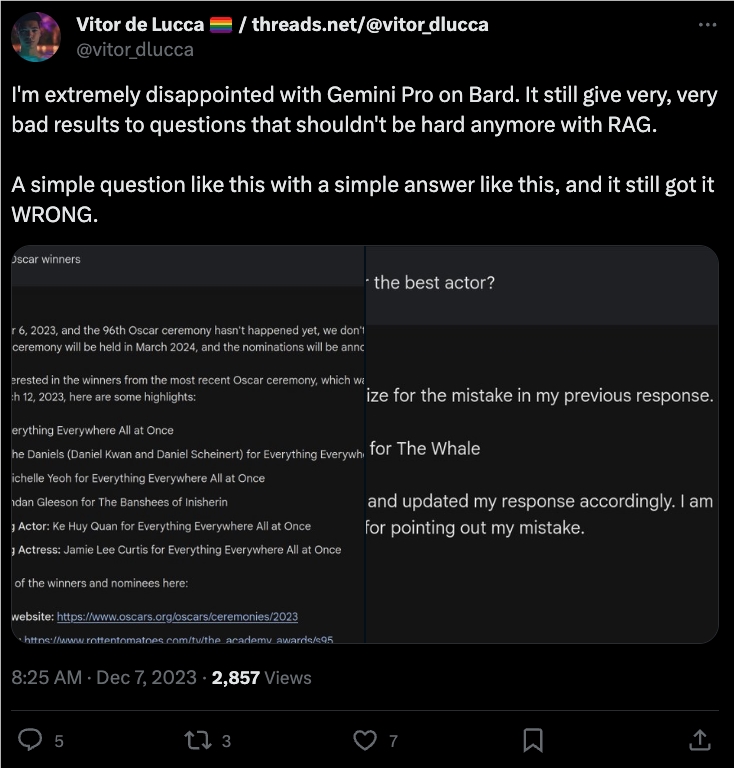
这位网友发出了自己测试基于Gemini Pro的Bard,对于很多事实类问题还是有错误。
他问了两遍Bard奥斯卡2023年的获奖情况,Bard给了两个不同的错误获奖名单。
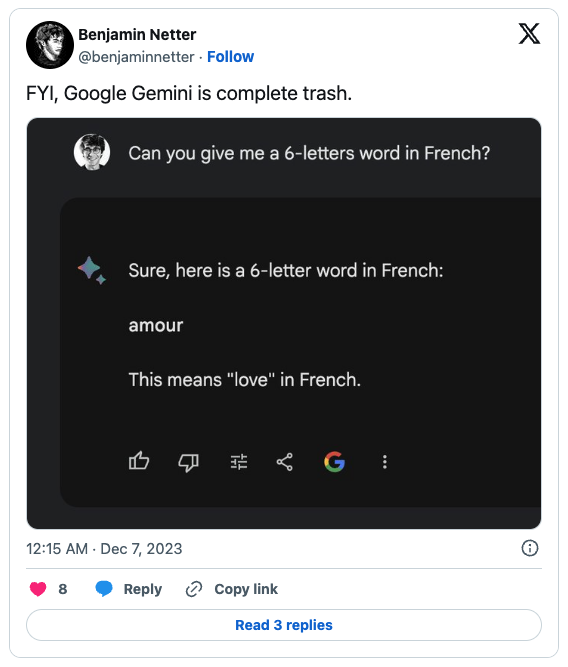
另一个网友又问了一个和翻译有关的问题,结果也不太对。
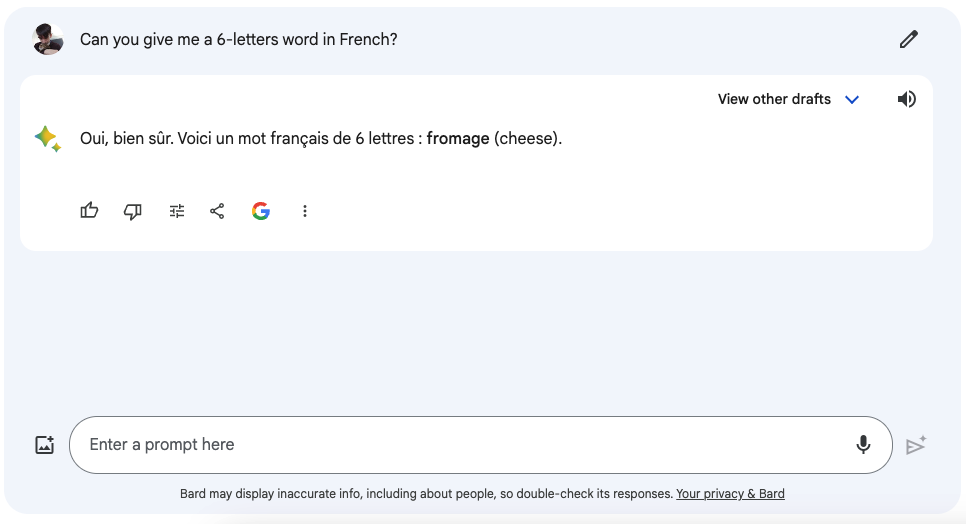
似乎它对语言中单词字数非常不敏感,经常会数错。
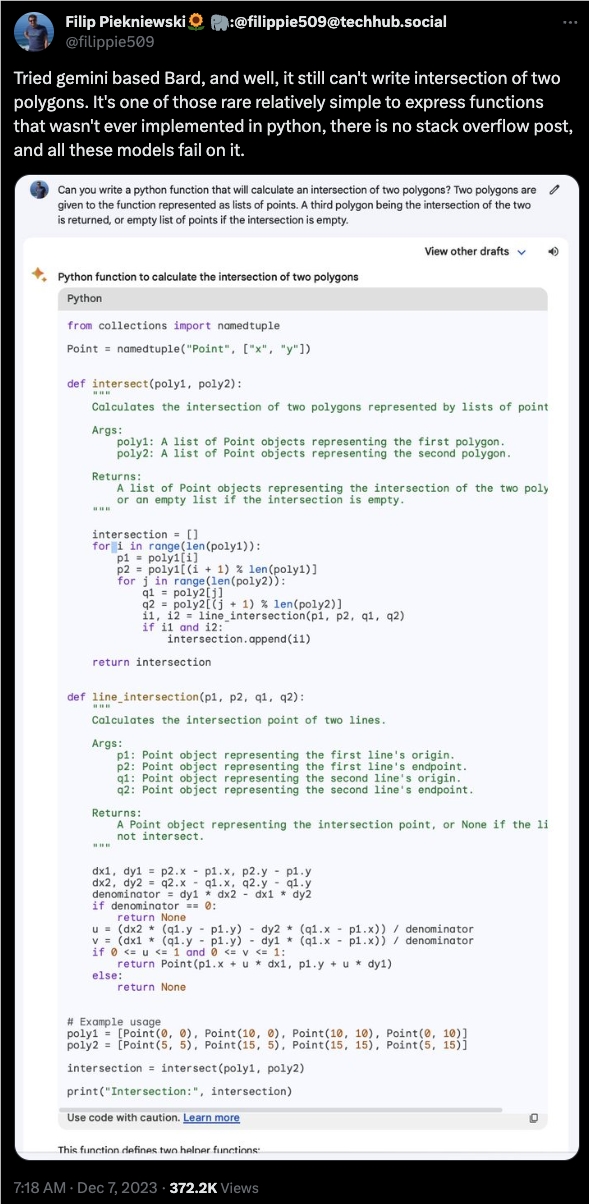
而对于谷歌重点宣传的代码能力,似乎Bard的表现也不够好,难道原因是在Stackoverflow上没有对应的答案?
还有人也模仿谷歌的行为,让ChatGPT从MP4中提取视频帧,然后解释视频......

ChatGPT自主从从视频中提取帧,然后网友上传6张对应图片,让ChatGPT给出具体的解释。


Gemini时代来临了
作为谷歌DeepMind的领导人,Demis Hassabis也是兴奋不已,并表示「Gemini的时代来临了」。
最新Wired的采访中,Hassabis直言道,谷歌今天宣布的人工智能模型Gemini为人工智能开辟了一条未被实践的道路,可能会带来重大的新突破。
「作为一名神经科学家和计算机科学家,多年来我一直想尝试创造一种新一代的人工智能模型。而这些模型的灵感来自我们所有感官互动和理解世界的方式」。
「Gemini是向这种『多模态』模型迈出的一大步」。
他继续道,「到目前为止,大多数模型都是通过训练单独的模块,然后将其拼接在一起,来实现多模态能力」。
「对于某些任务来说,这是可以的,但是在多模态空间中,无法进行深度复杂推理」。
这似乎是在暗指OpenAI的技术。
我们都知道,ChatGPT的多模态能力,是由GPT-4、DALL·E3、Whisper多个模型组合而实现的。
今年5月的谷歌开发者大会I/O上,劈柴首次官宣,谷歌正在训练一个新的、更强大的PaLM继任者,名为Gemini。
Gemini的命名也有深层的寓意,是为了纪念谷歌大脑和DeepMind两个团队实验室的合体,并向美国宇航局Gemini致敬。
7个月的时间,关于Gemini的各种爆料也是层出不穷。
而现在,谷歌以惊人的速度研发出Gemini,着实在年底之前来了一次重磅反击。
Hassabis说,新模型能够处理不同形式的数据,包括文本之外的数据,这是该项目从一开始就愿景的关键部分。
许多人工智能研究人员认为,能够利用不同格式的数据是自然智能的一项关键能力,而这正是机器所缺乏的。
ChatGPT等AI大模型因从强大的互联网数据中学习,获得了灵活且强大的泛化能力。
但是,尽管ChatGPT和类似的聊天机器人可以用同样的技巧,来讨论或回答有关物理世界的问题,但这种表面上的理解很快就会瓦解。
许多人工智能专家认为,要使机器智能取得重大进步,就需要AI系统在物理现实中赋予身体,即「具身」。
Hassabis表示,谷歌DeepMind已经在研究,如何将Gemini与机器人技术相结合,与世界进行物理互动。
「要实现真正的多模态,你需要包括触觉和触觉反馈。将这些基础型模型应用于机器人技术有很多希望,我们正在大力探索」。
目前,谷歌已经朝着这个方向迈出了一小步。
5月,该公司宣布了一款名为Gato的AI模型,能够学习执行各种任务,包括玩Atari游戏、为图像添加字幕,以及使用机械臂堆叠积木。
今年7月,谷歌RT-2机器人模型,便是通过语言模型来帮助机器人理解和执行动作。
为了让AI智能体更可靠,就需要为其提供动力的算法必须更加智能。
前段时间,OpenAI曾被曝出开发一个名为「Q*」的项目,网友纷纷猜测可能用到了「强化学习」,这是AlphaGo的核心技术。
不过,Hassabis称,谷歌目前正在按照类似的思路进行研究。
AlphaGo的进步有望帮助改善未来模型的规划和推理,就像今天推出的模型一样。我们正在努力进行一些有趣的创新,以将其带入Gemini的未来版本。
「明年,你将会看Gemini超强进化」。
看来,正如网友所说,我们离GPT-5降临的那一天也不远了。

现在,谷歌有Gemini,微软有GPT,Meta有LLaMA,Anthropic有Claude,这是否意味着苹果iPhone时代的终结?
参考资料:
https://twitter.com/parmy/status/1732811357068615969
https://techcrunch.com/2023/12/07/googles-best-gemini-demo-was-faked/
https://developers.googleblog.com/2023/12/how-its-made-gemini-multimodal-prompting.html
推荐站点
 77分类目录
77分类目录77分类目录(www.77dir.com)中国优质分类目录平台,为您提供免费分类目录提交,网站目录提交入口,中文网址目录收录,网址大全,网站大全,网站外链推广,软文发布等服务,为您分享优质正规的中文网站!
www.77dir.com YY分类目录
YY分类目录YY分类目录全人工编辑的开放式网站分类目录,收录国内外、各行业优秀网站,旨在为用户提供网站分类目录检索、优秀网站参考、网站推广服务。
www.yydir.com 名人百科网
名人百科网名人百科网(mrenbaike.net)--为大家提供各行各业的名人资料、资讯、图片等,致力于打造国内专业的名人百科平台!
www.mrenbaike.net 菜鸟教程
菜鸟教程菜鸟教程提供了基础编程技术教程。 菜鸟教程的 Slogan 为:学的不仅是技术,更是梦想! 记住:再牛逼的梦想也抵不住傻逼似的坚持! 本站域名为 runoob.com, runoob 为 Running Noob 的缩写,意为:奔跑吧!菜鸟。 本站包括了HTML、CSS、Javascript、PHP、C、Python等各种基础编程教程。 同时本站中也提供了大量的在线实例,通过实例,您可以更好地学习如何建站。 本站致力于推广各种编程语言技.
www.runoob.com 中国社会公益网
中国社会公益网陕西省社会公益基金会是经陕西省民政厅批准的公募基金会,下设秘书处、公益项目部、筹款募捐部、宣传策划部、社会活动部、专项基金部、资金管理部、公关联络部、青年志愿者工作委员会、青年志愿者爱心乐团等部门机构
www.cpf.net.cn CNMO科技新媒体
CNMO科技新媒体CNMO=Connect More,致力于通过内容成为人与科技、人与产品、人与品牌、人与服务对接的桥梁,让产业、产品的价值与服务得到专业且有趣的解读和适配,引领用户畅享科技带来的美好生活!
www.cnmo.com 国外主机测评
国外主机测评国外主机测评,国外VPS、云服务器,国外服务器,国外主机的相关优惠信息、商家背景、网络带宽、线路走法、售前和售后技术支持等,是目前最好的一家国外主机评测平台。
www.zhujiceping.com 赵容部落
赵容部落赵容部落,一个收集国内,国外便宜主机,VPS,云服务器,独立服务器优惠促销信息,提供VPS新手教程,VPS评测,VPS代购代付服务的博客。
www.zrblog.net 老左博客
老左博客老左博客,致力于美国VPS,美国主机评测、推荐;分享便宜VPS,美国主机优惠码,Godaddy优惠码,NameCheap等域名优惠码的IT博客,博主老左(LaoZuo.ORG)。
www.laozuo.org